Training is the most intensive -- and confusing part of Faceswap. Unfortunately, this part is more like an art than a science right now, and there is a ton of conflicting information out there. For this reason, we thought we'd collate all of the "best practices" on how to use Faceswap right now and give everyone a basic guide for how to ensure that they get the best results.
The following topics are all roughly in their order of importance. This may vary a bit (and individuals may disagree with my subjective ordering) but the advice here is the best that we currently know.
This one is critical. You really need to train from multiple sources. Don't just use one video for each A and B (In this guide, we'll also use Original for A and Swap for B) since that wont give the AI enough information to perform a proper swap. Failure to follow this advice will cause the AI to fail to learn enough to get proper color, probably wont get enough data to handle all expressions, and will almost definitely fail to give you a quality result.
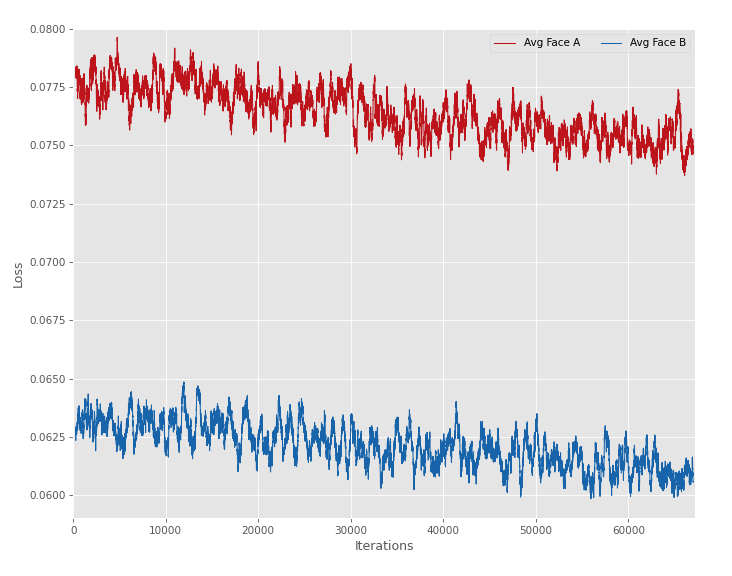
Use the Previews, not Loss or Iterations to decide when you're done
The only reliable way to determine if the AI is going to give quality results is to look at the previews. The 3rd column of each set of photos shows the Swapped face. This lets you compare to what the original face looks like as well as the swap. Ideally the swap should look exactly the same detail and quality as the original. This will never quite be the case and usually the swap will be slightly blurrier and less detailed. Unfortunately there is always some degree of loss due to how AIs work.
If one face's recreation is significantly worse than the other's (Judge by the face being put back on itself and not the swap) then you need to address this. This is sign of a data problem, getting higher quality and more data for the lagging face will be required to get a good result. Even if it's the Original face that is lagging if it's significant you need to address it or the swap will suffer.
Some people say you should look at the loss leveling out before you stop training. This is not recommended since loss only measures recreating the original faces (A-A and B-B) and cannot measure the quality of the swap. This, couples with something known as "overtraining" which will actually lead to worse results as time goes on. The only way to prevent this is to use the previews. However, there is another "treatment" for overtraining which can help a mildly overtrained model (Severely overtrained models will never be recoverable) this treatment is called Fit Training and is addressed below.
Youtube videos are quite low quality. They're heavily compressed, usually shot with bad lighting, and are NOT recommended unless there simply is no other way to get data. Some Youtube channels are better than others and may have 4K videos or high quality filming which might help to mitigate these problems, but you're still using a sub-standard data source.
Ideally you'd want to rip Blu-Rays (Or possibly very carefully selected DVDs) yourself. You don't have to get 4k quality from these, but you want to get the cleanest, best data you can. Ripping yourself is the only way to guarantee that you aren't dealing with substandard data. (Software to do this is outside the scope of FaceSwap and we don't officially endorse any software, but you can check out https://www.makemkv.com/ for a potential ripping software)
If you're filming yourself, then try to get a variety of lighting, expressions and poses. Also you should do everything you can to avoid motion blur and video noise. For these reasons we recommend using more lighting than you might think, going with a fast shutter speed, and using a tripod. If at all possible, film the same scene multiple times with different lighting colors. When this can't be done, you're going to be spending a lot more time postprocessing the results to get a reasonable output.
Part of this is trusting your source. Don't just remove all images that have a bit of blur or aren't perfect. The AI will experience those while swapping so needs to learn them early if you want it to be robust to those situations later. By all means, delete any images that are severely misaligned or don't show any usable face, but leave most other images you get from the extractor. The only exception to this would be if the lighting were so different it was hurting your training, in which case you might want to go back to the drawing board on which sources you select.
Select your Original and Swap faces carefully
You're not going to get good results putting a thin and angular facFit training with different Swap data is not required e onto a wide, rounded face. The data just isn't going to give you a good result. For this reason we recommend finding faces that are pretty similar in shape and dimensions (Relative, not absolute). Try not to swap a short face for a long one or to make excessive changes to the shape. The AI will dutifly swap them, but you're not going to get a good result without manually painting out the original face.
If you're shooting yourself and can't avoid swapping a smaller face onto a larger one then make sure to get background plates so that you can place the background back over the original face and apply the swap on top of that.
The AI can and SHOULD adjust for minor differences in skin tone. The Swap will be recolored to be more like the original in these cases. However, there is a limit to this, and the further from the Swap's original skin tone the worse the results will be. My golden rule applies here: Don't make the AI do any more than it has to. Try to keep the skin tones similar. Multiple sources with varied lighting will be more helpful for the AI to learn how to change the skin tone.
If you're changing skin tone I think it's very important to leave Color Augmentation ON for this. You'll get more accurate results.
Avoid beards that go outside the face area
Mustaches and subtle Goatees are fine, they'll be swapped just like any other facial detail but you really need to avoid beards in general. Anything that exits the face area will only be swapped inside the face area. Even if you're training on two people with similar beards they wont line up after the swap. There is unfortunately no way around this at this time, so we highly recommend that you avoid swapping any sources with beards.
Fit training is a technique where you train your model on data that it wont see in the final swap then do a short "fit" train to with the actual video you're swapping out in order to get the best results. This technique eliminates the danger of "overtraining" and produces clearer final results. To do this, you MUST follow the advice in our first section about getting multiple sources. It's impossible to fit train from a single source of data.
An example of this: If you were going to swap Nick Cage onto Harrison Ford as Indiana Jones you'd first train on data from (for example) Star Wars and Blade Runner (and maybe a scene or two from Indiana Jones that you're not swapping, ideally a different movie). This would be done until the quality from the swap looked good then once you're happy with those results you'd stop that training and give it the actual video you're planning on swapping. This would train for a much shorter time (Less than 10% of the original training) and should learn the subtleties of the new scene. Changing the Swap data for Fit training is not required but recommended to avoid the same overtraining problems.
This works even for a reused model where you have the same Original and Swap faces, since you can do multiple sessions of fit training on a model for different scenes. If you decide to do this, I recommend keeping backups before each fit training so that you can use the model that learned the swap best.
Don't Pretrain or Reuse models
You may have heard of Pretraining or reusing the same model for different faces proposed by other users, unfortunately doing what they say will only give worse results than a properly trained model. The benefits of pretraining or reusing a model is that it can improve training speed of a model, but at the cost of "Identity leakage" where a face just doesn't match the Swap's face properly. How the AI works is that it continuously refines the face that it has, but it is incentivized to only ADD to the knowledge so no mater if you retrain a model that was different faces or use a pretrained model you will get odd face mixing that will taint your results and make it look more like a different person.
There is a "safe" way to do pretraining/model reuse that avoids this particular drawback, unfortunately it requires a significant effort to get it working properly. To do this, you want to start a new model that matches the pretrained model, then replace the Encoder with the pretrained encoder. Unfortunately, this is not a perfect solution and will still take longer than a full pretrained model, but it does prevent the identity leakage situation.
EDIT: This is now officially supported by using the "Load Weights" option. Use of this option is detailed in the Training guide here: viewtopic.php?t=146#:~:text=Load%20Weights
HDR videos use a non-linear colorspace. The model wont be able to learn the face properly since the colors and lighting will be unreliable.
It's important to know that MOST but not ALL 4k movies are HDR. There is also no way to reliably un-HDR a movie for Faceswapping (at least without manually regrading the entire source). However, you can generally find a non-HDR version by getting a non-4k blu-ray which generally wont have HDR..