Page 2 of 2
Re: Potential VRAM Saving techniques
Posted: Tue Aug 23, 2022 7:39 am
by ianstephens
I have updated the above post with results after updating:
viewtopic.php?p=7422#p7422
As you can see, there is a definite improvement.
I will now move on to testing without central storage enabled.
Re: Potential VRAM Saving techniques
Posted: Tue Aug 23, 2022 11:47 am
by ianstephens
Utilization graph for DNY 1024 (1536px images) BS5 default strategy (all on GPU) before "caching/processing" has cycled through the entire dataset:
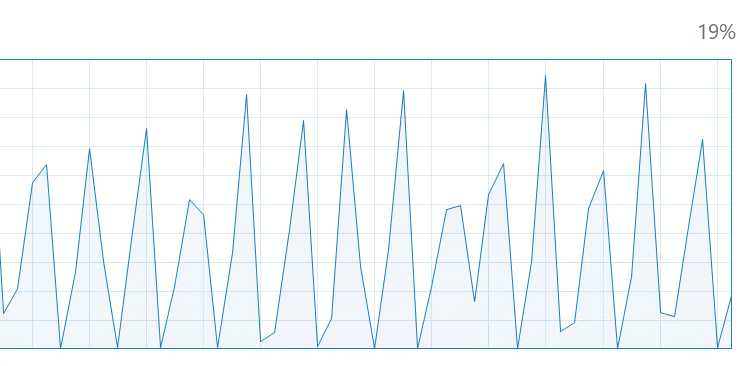
- Screen Shot 2022-08-23 at 12.44.00.png (112.17 KiB) Viewed 3404 times
After "caching/processing" has cycled through the entire dataset:
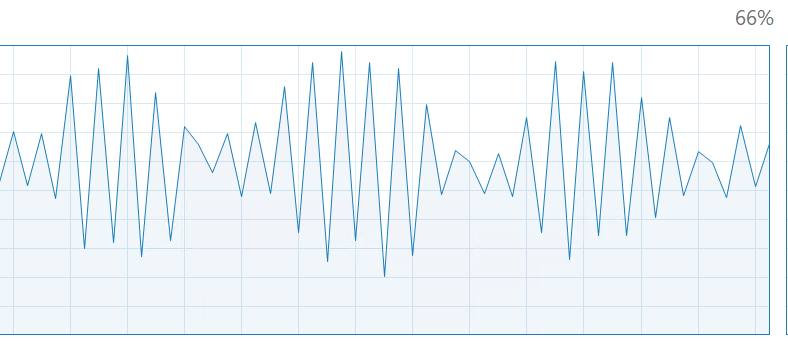
- Screen Shot 2022-08-23 at 18.27.24.png (72.62 KiB) Viewed 3395 times
Re: Potential VRAM Saving techniques
Posted: Tue Aug 23, 2022 11:59 am
by ianstephens
Fixes an issue where masks would sometimes be slightly misaligned
That's fantastic. I've hit this one a few times. The mask is accurate but not aligned correctly to the image.
Re: Potential VRAM Saving techniques
Posted: Tue Aug 23, 2022 5:30 pm
by ianstephens
I've just added the graph to show GPU utilization after I was sure the entire dataset had been cycled through:
viewtopic.php?p=7441#p7441
As you can see, GPU is utilized much more once this is cached/processed or whatever goes on behind the scenes.
However, of course, it's still (by a rough eye guess) only using ~ 60% of what the GPU can offer.
Hope this helps 
Any more tests you'd like me to run feel free to ask.
Re: Potential VRAM Saving techniques
Posted: Tue Aug 23, 2022 5:40 pm
by torzdf
That's useful information, thanks.
I have pretty much optimized the data processing pipeline as far as it will go at this point. It may be that it is still bottlenecking, or it may be that the large number/size of copies is the bottleneck.
The one other optimization I may be able to look at is parallelizing the image reads (specifically, reads are already parallelized, but they are done at the beginning of the data processing pipeline. I could look to load the next batch of data, whilst the current batch is processing). However, if you are reading from an SSD, I would not expect that to make a huge amount of difference.
I will add it to the list to look at at some point in the future.
Re: Potential VRAM Saving techniques
Posted: Wed Aug 24, 2022 10:04 pm
by ianstephens
I can't work out why I'm now able to run BS5 all-on-GPU with the existing 1024 model I have been working with. It's stable too and no OOM with certain batches and having to drop down an integer.
Could it be to do with, "Process data at model input/output size rather than saved image size"?
Re: Potential VRAM Saving techniques
Posted: Wed Aug 24, 2022 10:28 pm
by torzdf
The image processing is all on the CPU, so won't impact batch size at all.
How Tensorflow works internally is a complete mystery to me :/
Re: Potential VRAM Saving techniques
Posted: Sun Nov 06, 2022 5:52 am
by MaxHunter
The other factor is that bigger and more complex models need lower learning rates. Latest models I'm developing need to be starting at between 1e-5 to 3e-5. That is also just a matter of fact.
Yet another factor feeding this is that batch size is proportional to learning rate. If you lower the batch size, you should lower the learning rate. This is kind of logical, as smaller batch-sizes mean that outliers will have a larger effect on gradients. As models get larger and more complex, lower batch sizes are unavoidable. There has been some recent research around this, which I have not yet had an opportunity to fully digest: https://arxiv.org/abs/2006.09092
I'm using the DNY512 with MS-SSIM and lpips-VGG at 5%. Because of this I'm only able to eek out a batch size of one. Fine. Slow and steady wins the race.
I've been experimenting/learning with/about proper learning rates , and after reading this post multiple times over the course of learning I read the above paper tonight (most of it at least, because the math is FAR too advance for me.) In the conclusion of the paper (point 2), if I'm understanding it correctly, it says the learning rate should be equal to the square root of the batch size. If my batch size is 1, than the square root would be one, and there for my learning rate according to this paper would be.... (If this is an obvious question please hold your snickers until I leave the room. Thank you.)
(If this is an obvious question please hold your snickers until I leave the room. Thank you.)
Re: Potential VRAM Saving techniques
Posted: Sun Nov 06, 2022 12:35 pm
by torzdf
I don't think its as simple as that, so know I don't think your missing anything. My main takeaway (iirc) was that Lr needs to be lowered if BS is lowered. I didn't really look too closely into ratios/equations etc, as I would imagine that this would vary wildly on a case by case basis.
Re: Potential VRAM Saving techniques
Posted: Sun Nov 06, 2022 6:59 pm
by MaxHunter
Thanks for answering. If what I read was correct than I figured the learning rate would have to be 1e-1 because (I had to double check with Google,) the square root of one is either 1 or -1, and based upon our past conversation about what the learning rate formula represents, this would make it correct, right?
I'm just wondering more for curiosity, is there a way to check this with FS? Because the learning rate doesn't go down that low. Can I just input this figure and see what happens or will it just default? (Again, just a curiosity question.)
Re: Potential VRAM Saving techniques
Posted: Thu Jan 19, 2023 8:18 pm
by couleurs
@MaxHunter If I understand that section of the paper correctly, they say that specifically using Adam optimizer learning rate scales proportionally to square root of batch size. This is very different from saying that the LR is square root of batch size.
Essentially they are saying that if you have a good LR using Adam optimizer at Batch Size X and want to go to Batch Size Y, you should multiply the LR by ratio of (square root Y):(square root X)
This is still pretty useful to know even if it doesn't give an absolute value of learning rate
Using the default FaceSwap value of 5e-5 which I believe is intended for use at BS=16, this gives us:
| Batch Size | Learning Rate (e-5) |
|---|
| 16 | 5 |
| 12 | 4.33 |
| 10 | 3.95 |
| 8 | 3.54 |
| 6 | 3.06 |
| 4 | 2.5 |
| 2 | 1.77 |
| 1 | 1.25 |
Re: Potential VRAM Saving techniques
Posted: Fri Jan 20, 2023 12:25 am
by torzdf
Actually, theoretically the initial 5e-5 learning rate came from a batchsize of 64.
However, it's a little less clear cut than that, as back then the model would feed the A side and the B side consecutively (so there would only ever be 64 faces in the model at one time).
Now we have a batchsize of 16, but both sides are fed at the same time, meaning that there are 32 faces in the model at one time.
Regardless, the overarching calculation for adjusting learning rate is good.
Re: Potential VRAM Saving techniques
Posted: Fri Jan 20, 2023 5:36 pm
by MaxHunter
@couleurs
Wow! Thanks for breaking that down for me! Good stuff!
So to be clear, based on your calculations and table, my learning rate for a batch size of one would be, 1.25e-5, right?
Re: Potential VRAM Saving techniques
Posted: Fri Jan 20, 2023 6:05 pm
by couleurs
The really important and subtle part is if you have a good LR for a given model.
What makes an LR good depends on a ton of things, including model structure, model size, loss function, and so on. In the context of this thread, we are dealing with running huge models that can only run at BS=1 or 2, so we can't confirm that 5e-5 at BS=16 is actually a good learning rate.
If you have a model that is running really well at a given LR/BS on a single beefy device and you want to run it in parallel on many smaller devices then you have to scale the batch size down - this gives a guideline of how you do should go about scaling LR correspondingly.
However if you change anything other than the batch size - e.g. changing loss config - then you have (probably) affected the optimal learning rate in a different way. If the changes aside from the batch size are small, then the square root scaling is probably a good general ballpark of where the optimal LR is at this new batch size.
In all cases this shouldn't be interpreted as anything more than an estimate.
Re: Potential VRAM Saving techniques
Posted: Sun Feb 05, 2023 6:08 am
by MaxHunter
Because I haven't done this type of math in years, and had to figure it out on my own. Since the original formula was for BS 64, then the formula for a BS 1 would look like this: √1÷8x5=.625
.625e-5=6.25e-6
Right?
I know this isn't an accurate learning rate, but I'm curious if I figured out the formula correctly.
 (If this is an obvious question please hold your snickers until I leave the room. Thank you.)
(If this is an obvious question please hold your snickers until I leave the room. Thank you.)